

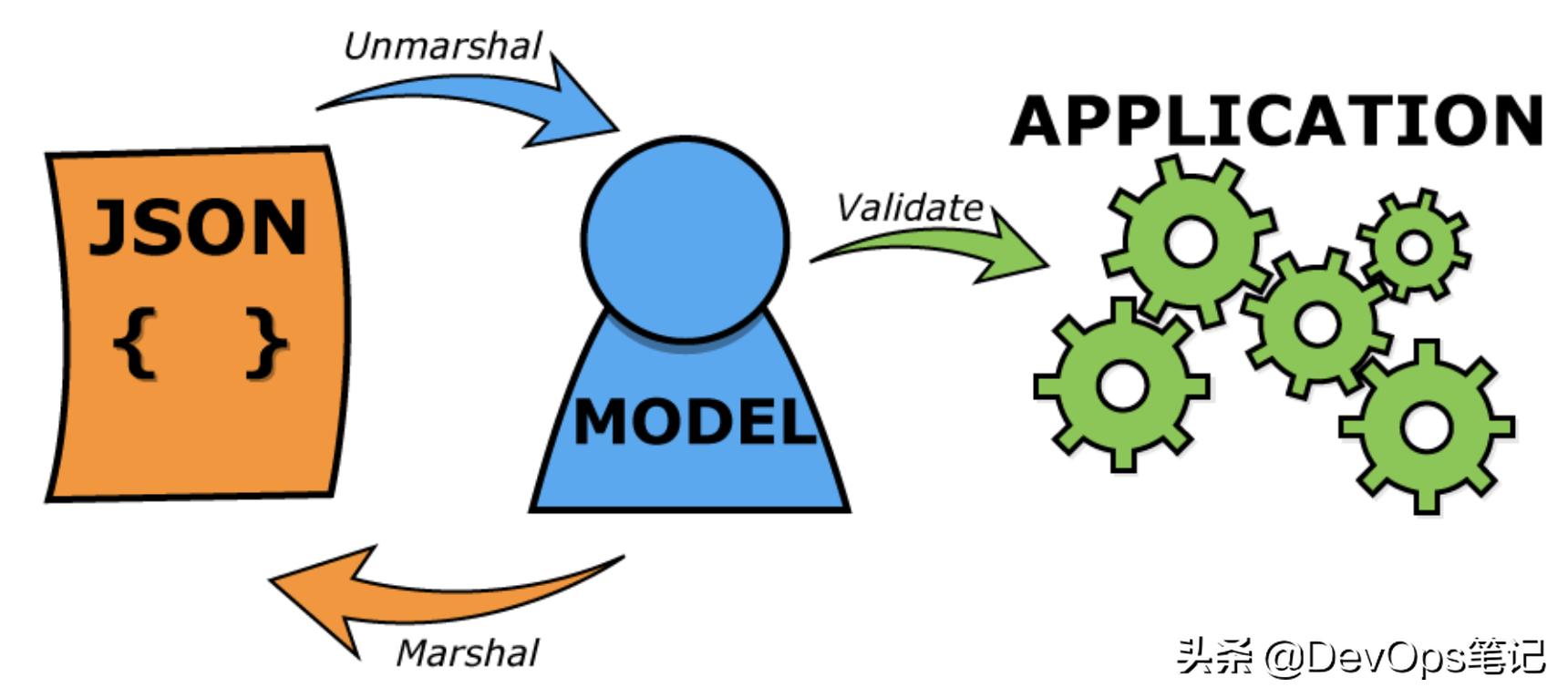
要让大语言模型输出JSON格式,可以通过编写相应的代码或脚本,将模型的输出转换为JSON格式。具体而言,可以在模型输出后使用编程语言中的JSON库或函数,将输出数据转换为JSON格式,并将其以字符串的形式返回。还可以考虑在模型设计过程中,直接设计输出层以产生JSON格式的输出,这样可以更直接地控制输出的格式和内容。实现大语言模型输出JSON格式需要结合具体的编程语言和模型框架,通过编写相应的代码或脚本实现。
大语言模型概述
大语言模型是近年来人工智能领域的重要突破,它们基于深度学习技术,尤其是Transformer架构,能够处理大规模的文本数据,这些模型通过预训练方式学习语言的统计规律,然后在各种自然语言处理任务中进行微调,达到很高的性能,它们广泛应用于文本生成、情感分析、问答系统、机器翻译等领域。
将大语言模型输出转换为JSON格式的方法
1、选择合适的大语言模型框架
目前,有许多优秀的大语言模型框架可供选择,如BERT、GPT系列等,这些框架通常提供预训练模型和API接口,方便开发者进行模型的调用和输出处理。
2、获取模型的输出
通过调用大语言模型的API接口,我们可以获取模型的输出,这些输出通常是字符串形式,包含了对输入文本的分析和预测结果。
3、将输出转换为JSON格式
将模型的输出转换为JSON格式需要一定的处理,我们需要根据模型的输出格式,使用正则表达式、字符串分割等方法将输出字符串解析为Python中的数据结构(如字典、列表等),我们可以使用Python的json模块将解析后的数据转换为JSON格式。
在解析和转换过程中,可能会遇到一些挑战,不同的大语言模型可能有不同的输出格式,需要根据具体情况进行解析和处理,为了后续的数据处理和存储方便,我们需要根据实际需求设计合理的数据结构,在进行字符串解析和JSON转换时,也需要进行异常处理和错误检测。
示例代码(修正和补充)
下面是一个简单的示例代码,演示如何将大语言模型的输出转换为JSON格式:
import json
from some_library import load_model # 假设有一个加载模型的库函数
加载大语言模型
model = load_model() # 加载预训练模型
输入文本
input_text = "请输入文本..." # 这里填写需要处理的文本数据
获取模型的输出
model_output = model.predict(input_text) # 假设predict方法返回模型的输出字符串
解析输出字符串为Python数据结构(此处需要根据实际输出格式进行解析)
parsed_output = parse_model_output(model_output) # 这里填写具体的解析函数实现
构建JSON对象(根据实际需求和输出格式构建合理的JSON结构)
json_obj = {
"input_text": input_text, # 添加输入文本信息便于后续分析
"model_output": parsed_output # 将解析后的输出添加到JSON对象中
}
转换为JSON格式字符串并打印输出
json_str = json.dumps(json_obj, ensure_ascii=False, indent=4) # 格式化输出JSON字符串,确保非ASCII字符正常显示
print(json_str) # 输出格式化后的JSON字符串注意事项(补充)
1、输出格式的多样性:不同的大语言模型可能具有不同的输出格式和细节信息,在进行解析和处理时,需要根据具体模型的特点和要求进行相应的调整和处理。
2、数据隐私和安全:在处理涉及敏感信息的文本数据时,需要注意数据隐私和安全保护的问题,确保数据的合法获取和使用,并遵守相关的法律法规和隐私政策。
3、性能优化:对于大规模文本数据和高性能要求的应用场景,需要考虑模型的性能优化问题,选择合适的模型和框架,并进行适当的参数调整和优化,以提高处理速度和准确性。
通过以上补充和修正,您的文章将更加完善,能够更好地帮助读者了解如何将大语言模型的输出转换为JSON格式,并更好地应用这些模型进行数据处理和存储。
 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号